Whisper模型 最先進的語言辨識 20240705,這次的重點放在whisper模型,為了要展示最強語言辨識的能力,我還特別去了健身房,在吵雜的背景下錄了1分鐘的說話,分別讓不同大小的語音辨識模型,展示分辨惡劣環境下語音的能力,對了~這一篇文章的逐字稿,也是由模型聽打出來的喔!

Whisper模型 影片
Whisper模型 最先進的語言辨識

- 2024075 股市看不懂
- Whisper模型是什麼?
- 語音辨識實際測試
- Whisper模型的種類
- 語言辨識的近況
嗨我是亞瑟我有三高
今天是2024年7月5號
今天要來講最先進的語言辨識
那就是Whisper模型
今天一樣會講股市但是講不多
因為我們還是要回到我最喜歡講的主題
那就是我正在研究的事情
這一次為了測試這個語音模型
還加入了實測哦
歡迎各位和我一起往下看
2024075 股市看不懂
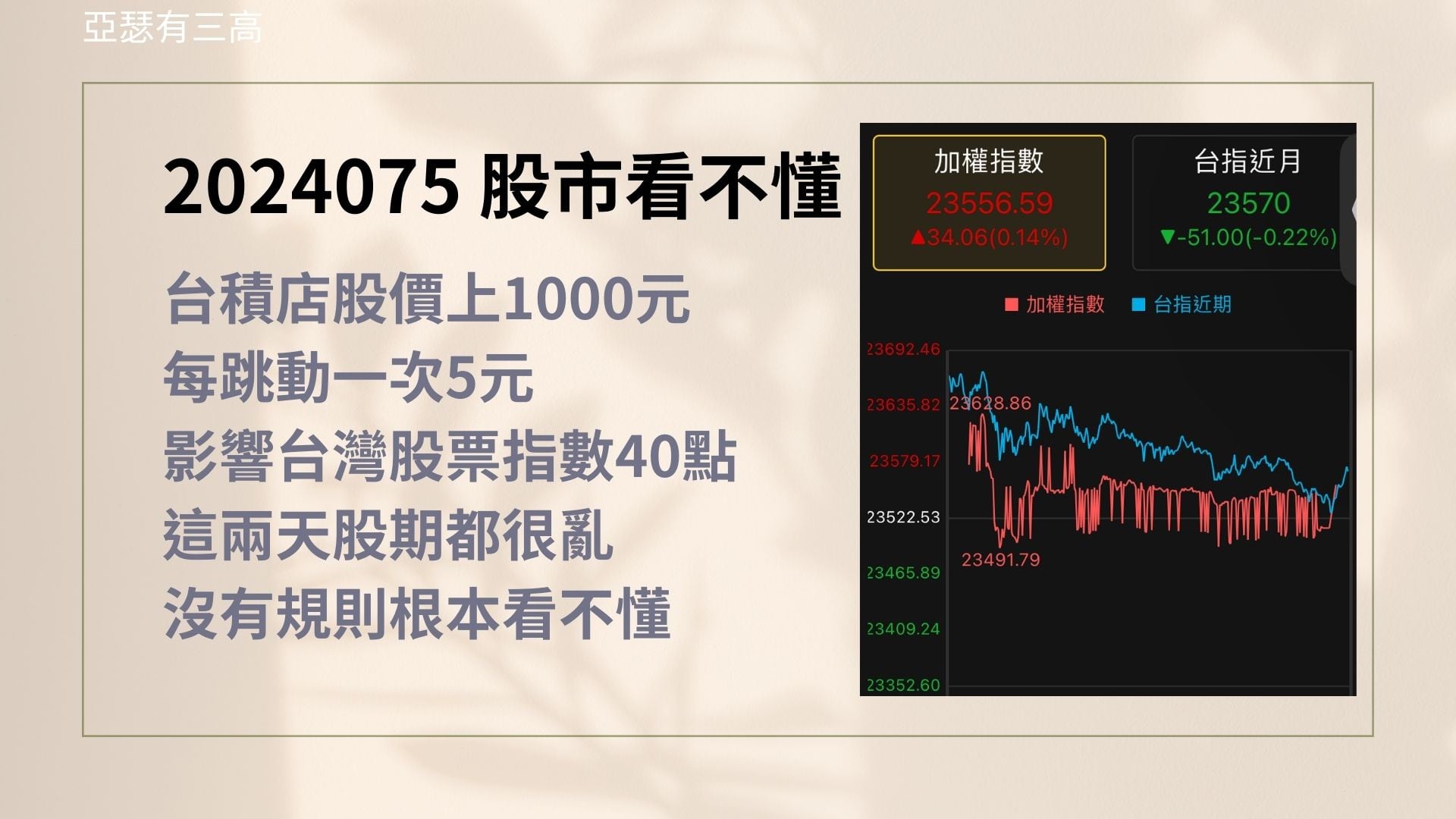
- 台積電股價上1000元
- 每跳動一次5元
- 影響台灣股票指數40點
- 這兩天股期都很亂
- 沒有規則根本看不懂
今天是2024年7月5號
台積電昨天股價又上了一千元
今天是第二天
上了一千元之後呢
股市就變得很難做
因為一千元以上的股票
每一次漲跌幅都是五塊
那因為台積電的權重很高
所以它每跳動一次就要影響40點
所以各位可以看一下螢幕上面
這個指數就是每一次台積電跳動
就會導致這樣子的狀況
除了台積電誇張的指數變動之外
還有投資人過分的熱情
照理而言
期貨的數字應該要比
指數的數字再低一點
低100點左右
因為要除息
可是呢不知為何
依舊是比它高
所以這兩天不管是股市也好
期貨也好都很亂
實在是看不懂
每次做呢都每次賠錢
昨天呢認為應該要有逆價差
所以昨天賠錢
今天想說好吧那就正價差吧
結果今天還是賠錢
因為今天正價差收斂
哎呀真是沒有規則看不懂啊
看不懂看不懂閃
Whisper模型是什麼?

- OpenAI 開發
- 語音辨識模型
- 專門將語音轉為文字
- 多語言和多口音
- 並能處理背景噪音
我們來講這次的重點
那就是Whisper模型是什麼
Whisper模型是由OpenAI開發
是它的專利哦
專門給語音辨識來使用的模型
它最大的能力就是把語音轉成文字
而且因為它特別技術
所以它可以融合各種語言
甚至是各種口音
甚至是在吵雜的地方
一樣可以把語音清晰的轉成文字
這是它非常非常厲害的地方
也是它的特色
所以Whisper是目前最強的語音辨識模型
語音辨識實際測試

- 健身房實際錄音
- 踏步機上講話一分鐘
- Whisper大型模組
- 幾乎沒有錯誤的辨識
- 小模組也免強能理解
如果只是吹噓
那麼大家當然不信
所以在這邊要為各位去健身房
實際走一次
我呢會在健身房的踏步機上面
一邊喘氣一邊和Whisper模型講話
Whisper的大型語言模組
它可以在幾乎沒有犯錯的情況之下
辨識我的聲音
當然啦小一點的模型呢
也能夠勉強理解
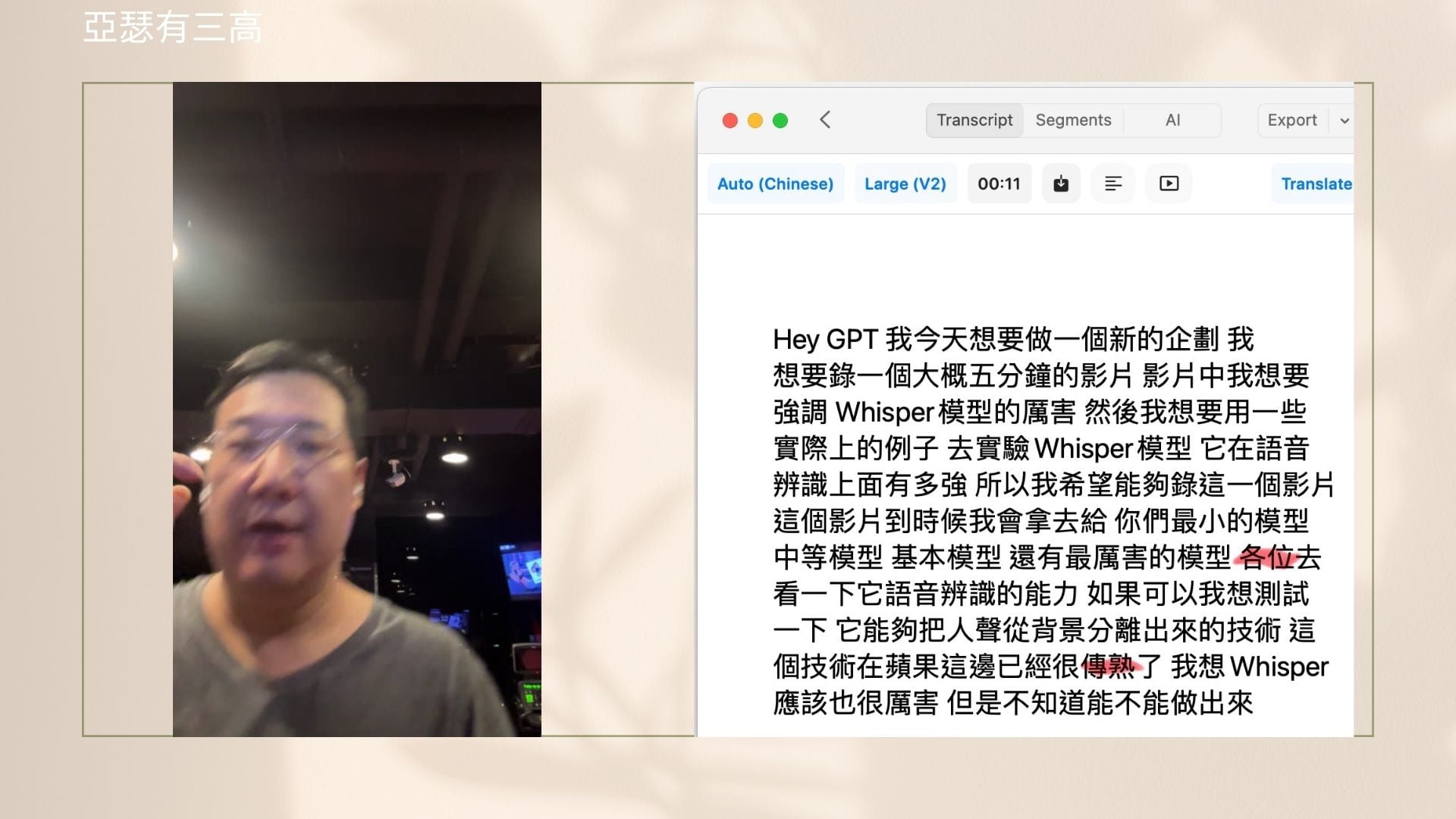
接下來請各位聽一下我這一分鐘的錄音
有點吵我不會做任何的修飾
請各位稍微忍耐一下
嘿GBT
我今天想要做一個新的企劃
我想要錄一個大概五分鐘的影片
影片中我想要強調
Whisper模型的厲害
然後我想要用一些實際上的例子
去實驗Whisper模型
它在語音辨識上面有多強
所以我希望能夠錄這一個影片
這個影片到時候我會拿去給
你們最小的模型中等模型
基本模型還有最厲害的模型
讓你們去看一下它語音辨識的能力
如果可以
我想測試一下它能夠把人聲
從背景分離出來的技術
這個技術在蘋果這邊已經很成熟了
我想Whisper應該也很厲害
但是不知道能不能做出來
而在螢幕的右邊
就是這次由Whisper幫我解譯出來的
有紅色的字標示出它沒有譯好的部分
其實就差一兩個小小的字而已
原則上它的達成率非常的高

當然我把不同大小的Whisper模型
解譯出來的答案都放在這邊
它的Tiny模型真的有點糟
各位請注意它的Base模型
等一下我們要特別強調Base模型有多厲害
Whisper模型 的種類

- Tiny – 72 MB/1GB/1TOPS
- Base – 142 MB/2GB/2TOPS
- Small – 466 MB/4GB/4 TOPS
- Medium – 1.5 GB/8GB/8 TOPS
- Large – 2.9 GB/16GB/16TOPS
接下來我們要看到Whisper模型的種類
它大致上分成五個等級
分別從Tiny、Base、Small、Medium到Large
最厲害的當然是Large
但是Large模型它很大
它的模型至少要2.9G
需要16G的記憶體
而且需要16TOPS的AI運算能力
所以它可能不適合用手機來處理
但是電腦是OK的
尤其是有AI運算能力的電腦
再來是重點來剛剛那個Base模型
它的大小只有142MB
也就是說比這支影片還有小
運行它只需要2G的記憶體
所以各位的手機都可以跑
另外只需要NPU2的運算能力
換句話說iPhone X都有執行它的能力

接下來把Whisper模型
它所有的需求跟它的內容
顯示在上面
因為我們不是一個科技頻道
所以我們就不再去強調中間的差異性
我們所要知道的事情是
這個模型目前在蘋果已經出的Notebook上面
是可以用95%的能力去辨識中文的
那麼也可以在很舊的手機上面
也有70%的辨識能力
坦白說這是一個非常非常厲害的成果
但是我剛剛是在一個非常吵雜的情況下
有喘氣的情況之下
測試中文測試出這樣子的結果
可見得目前語音辨識的技術
已經是非常非常的厲害了
語言辨識的近況

- 目前Whisper 最厲害
- 蘋果Google跟微軟
- 目前僅限英文準確
- 中文辨識力還不夠
- 語音辨識並不簡單
接下來我們就來稍微聊一下語音辨識的近況
由於我接觸這個模型
使用這個模型已經有一陣子了
所以我已經不再覺得它很厲害
甚至也不會為了它的表現而訝異
但是我想沒有玩過這個模型的
應該看到這樣子的測試會非常訝異
它怎麼這麼厲害
是的沒有錯真的厲害
目前來說Whisper模型是最厲害的了
雖然蘋果Google跟微軟
也有自家的語音辨識模型
但是目前測試下來
應該只有英文比較準確
而且需要比較安靜的環境
再來他們中文的辨識能力還不夠
目前他們只訓練了英文而已
還沒有把其他語言都完整訓練進去
所以可見得
語音辨識並不是一件容易的事情
Whisper模型已經出來超過半年以上了
甚至各位聽到的這一個影片
它的字幕也是由Whisper模型完成的喔
準確率應該高達95%以上
想當年我們上第一個影片的時候
為了一個十分鐘的影片
都要花一天的時間去打中文字
現在Whisper模型只要花幾秒鐘的時間
是的就幾秒鐘的時間
就可以把這個影片的字幕給完全解析出來
而且還幫我對上時間軸喔
所以啊AI正在淘汰沒有用的人啊
趕快跟上喔各位
好那今天我們的講解就到這
下次見 拜



