Whisper語言模型 三巨頭都不用 期貨嘎空手 20240708,原本以為Whisper模型是最強的語音識別系統,所以三大巨頭iOS、Windows、Mac應該要採用,但實際上並非如此,原因有三項將分別解釋: 專利權利限制、整合作業系統、現有技術衝突。另外聊台股非漲我期貨嘎空手~

Whisper語言模型 三巨頭都不用 影片
嗨我是亞瑟我有三高
今天是2024年7月8號
今天要來談的是
Whisper語音識別三巨頭都不使用
以及今天期貨市場
我是被軋空手的狀況
Whisper語言模型 三巨頭都不用

- 期貨嘎空手20240708
- 最先進語音辨識
- 三巨頭都不用
- 專利權利限制
- 整合作業系統
- 現有技術衝突
- Whisper模型 總結
原本我以為Whisper模型
是最強的語音識別系統
所以三大巨頭iOS、Windows
Mac應該要採用
但實際上並非如此
為了要知道事實
所以我就深入去研究這個議題
這個非常冷門的議題
結果發現很多事情
是和我當初了解的完全不一樣的
這東西對我而言是很興奮的
所以我拿出來分享
畢竟這是我的日記嘛
當然我們來再看一下期貨的部分
期貨嘎空手20240708
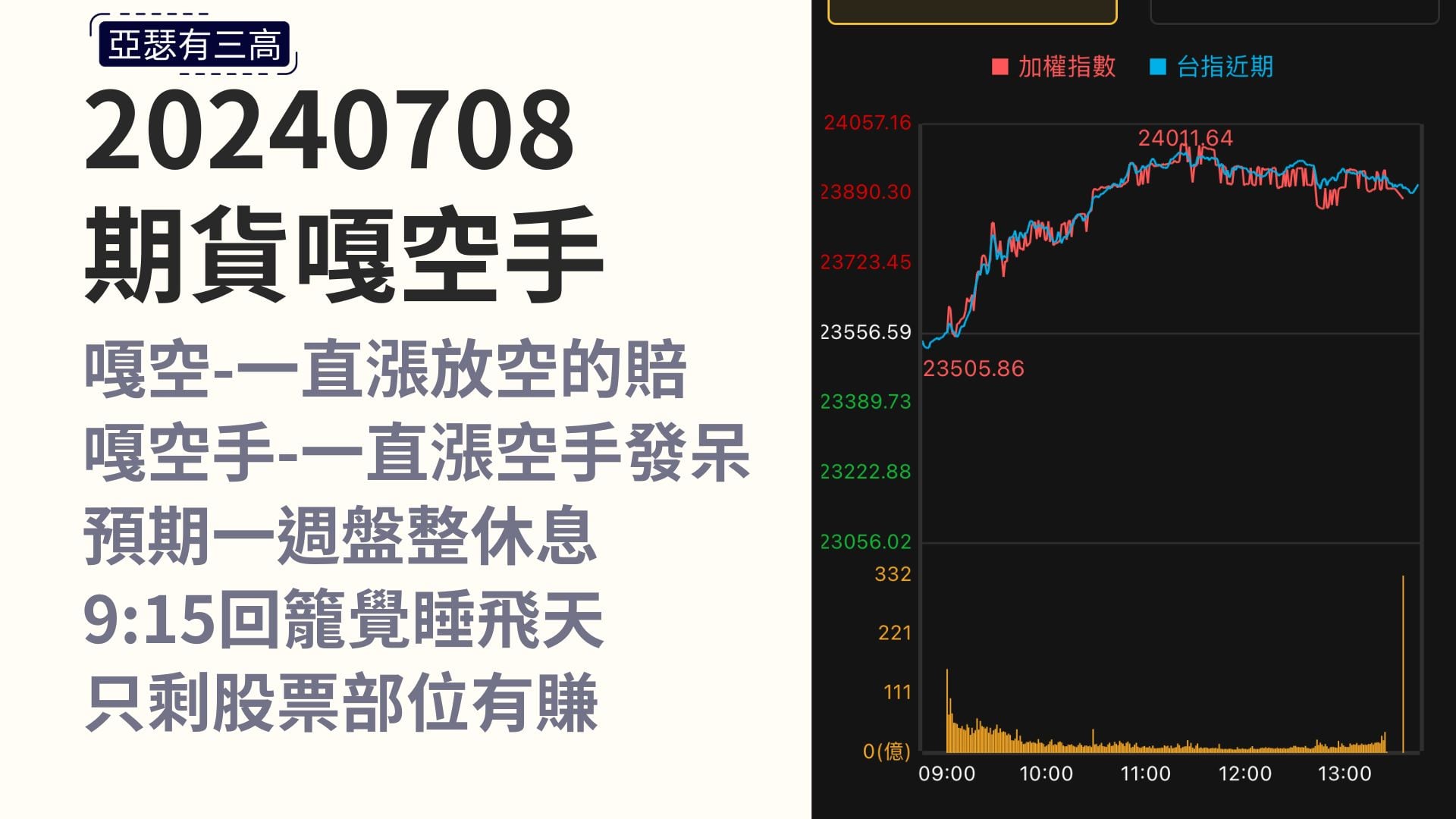
- 嘎空-一直漲放空的賠
- 嘎空手-一直漲空手發呆
- 預期一週盤整休息
- 9:15回籠覺睡飛天
- 只剩股票部位有賺
今天是2024年7月8號
今天我的期貨是被軋空手
然後解釋一下軋空的意思
軋空就是指說
你本身是放空的
可是市場卻一直漲
那這個時候呢
你就會一直賠一直賠一直賠
被軋到死掉這叫做軋空
那什麼是軋空手呢
那就是我手上什麼都沒有
然後卻一直漲
然後又一直不敢進場
這就叫做軋空手
今天我就是一個軋空手的一天
原本預期台積電一千塊之後
應該就卡在那邊不會動了
因為它已經卡兩天了嘛
再加上今天是禮拜一
理論上來說
今天是一個比較peace的一天
當然啦我還是很早起
七點半就起床了
大概九點十五分的時候
我就覺得哎呀量縮了啦
果真是盤整盤啊
我好累喔我就睡覺了啦
本就是收手的時候沒打算要進場
所以我就去睡覺了
在睡覺的時候意識中還夢到
我醒來看了一下那個手機
就發現喔是盤整盤
所以我就繼續睡
而且這還夢了兩次喔
這個盤裡面在股市裡面能賺錢
一定要夠勤勞不可以偷懶
偷懶就會這樣
最先進語音辨識

- Whisper語言模型
- OpenAI開發擁有
- ChatGPT兄弟
- 最佳狀況中文97%
- 最小模型中文70%
接下來要講Whisper語音模型
Whisper模型是由OpenAI所開發的
它是目前最先進的語音識別系統
它本身呢有大、中、小模型
有好幾種版本
但是它目前最大的模型
它的中文辨識率高達97%
甚至在很吵雜的情況之下
講話有口音又喘氣又不清的情況之下
也有90%以上的辨識率
另外它的小模型很小很小的模型
其實也有70%的辨識能力
如果說大家想要知道
它到底有多強的話
其實看上一篇上一篇我有做實測
有做這樣子的解釋可以去了解一下
實際上來講即使是非常小的設備
非常簡單的設備用非常小的模型
也能夠大致辨識出
中文語音講話的內容喔
這一個影片它的字幕
應該是由Whisper模型來幫我上的
如果我沒猜錯的話
它的準確率應該高達95%
感謝Whisper
三巨頭都不用

- iOS Android Windows
- 不採用 Whisper 模型
- 專利權利限制
- 整合作業系統
- 現有技術衝突
儘管Whisper模型這麼厲害
可是很可惜的是
iOS、Android跟Windows
都沒有打算要採用Whisper模組
更好玩的事情是我原本以為
未來就會是了
因為有一些人是OpenAI的爸爸
有一些人是OpenAI的好兄弟
而且現在大家都有跟OpenAI做合作
怎麼可能不使用呢?
可是研究之後才發現
這三巨頭的語音識別技術
雖然跟Whisper模型還有很大的差距
可是他們有100%不採用的原因
而且他們未來
也不會採用Whisper語音模型
主要的原因有三大個
下面我們會分別來講
第一個是專利問題
再來是操作系統整合的難度的問題
再來是和現有技術衝突的問題
專利權利限制

- Whisper是OpenAI專利
- 不是開放原始碼的方案
- 程式碼和訓練數據未公開
- 直接整合這項技術
- 需處理法律和商業問題
首先當然是專利的問題
Whisper模型雖然是OpenAI的專利
而且還開放大家使用
甚至我們可以去下載下來
在本地端做使用非常的大方
所以我一直以為它是開放原始碼
結果沒想到它不是開放原始碼
它只是開放讓你們使用而已
這個模型的原始碼
和訓練的數據都沒有公開喔
如果要深入討論的話
也許它的內容有一些侵犯隱私
專利或是作權的問題
這也使得三巨頭無法直接整合這個模型
到他們系統裡面去
因為如果未來發現有隱私的問題
涉及專利的問題
那麼他們的系統可能就要重新打掉重做
直接整合Whisper語音模型
會面臨到未來
可能會有的法律和商業問題
這個使得三巨頭不會願意
現在把它整合進去
他們寧願自己開發
整合作業系統

- AI系統需深度整合
- 非單純文字輸入輸出
- 上下左右前後
- 基本圖形與畫面感知
- 更多模糊的辨識能力
再來要談到的當然是
操作系統的整合難度
因為要把AI整合進作業系統裡面
不是簡簡單單的文字輸入跟輸出
它不是輸入法而已喔
AI整合進系統之後
它要面對的問題不是替代輸入法
它要替代的將會是
整個使用者介面我們叫UI
例如說我們可能會有上下左右
前後的一個識別方式
甚至我們還有圖形圖像
或是畫面的感知能力
舉個例子來說
我們可能會和電腦說
我要比較圓的那個比較亮的那個
比較醜的那個比較高的那個
這件事情它其實是
比語言模型還要困難很多很多的
我們在語音識別的時候
是追求百分之百的準確
但是我們在理解人類語境的時候
追求的可能是大致上了解就可以過關
所以它並不適合
直接整合到整個作業系統的底層去
整個作業系統需要更厲害的AI
或者說是能夠接受
模糊識別能力的AI模組
現有技術衝突

- iOS-核心用自家技術
- Siri訓練很已久且合法
- Android-Gemini AI
- Google語音曾最先進
- Windows-Copilot
- 基礎己內建或聯網
最後談到當然是和現有的技術衝突
像是各大公司早在之前
就已經準備好了自己的技術了
例如說像蘋果就使用自己的技術
它有Siri嘛
各位對Siri應該都很了解
Siri已經訓練很久了
而且還合法授權使用
各位你們和Siri講話的時候
錄音、文字、你的選擇
都已經被擷取下來
而且你們當時都同意的
所以這個內容合法龐大而且不會被告
那談到Android呢
其實Google也有自己的GeminiAI
Google語音識別技術
曾經是業界的最厲害
而我們之前也一直使用
Google的語音識別技術
來幫我們做服務的
在未來Google也可能
等大家打爛了之後
再把它的技術免費分享出來給大家用
那大家就只能綁在Google上面了
例如YouTube例如Gmail
再來是Windows
Windows也有自己的AI啊
Microsoft的Copilot
而且它語音識別技術
已經在Windows已經內建很久了
在Windows裡面
本來就有語音輔助的操作功能
去協助需要協助的人
甚至它還有另外一個可以連網的AI
去理解你更多的操作
跟你更多的需求
雖然它的質量很差
但以微軟過去的經驗來說
它絕對會把它自己的東西堅持修到堪用
因為微軟必須要承諾
它要和之前的系統之前的API
之前的各家合作軟體做合作
所以不太會去大力更改
自己系統底層的功能
Whisper語言模型 總結

- Whisper專精語音識別
- 無自然語言處理NLP
- 相對精簡與單功能
- 適合邊緣輕量化計算
- 智能設備/物聯網IoT
- 語言教育與障礙輔助
接下來我們來個總結一下
Whisper語音模組
它本身專精於語音辨識
和一般擁有自然語言能力
處理情感分析的AI模型不同
所以它沒有所謂的NLP
自然語言處理的能力
它更精簡而是專精於把語言轉譯成文字
所以它更適合邊緣運算和輕量化計算
例如說像是智能設備或物聯網設備
我們舉個例子來說它更適合物聯網
例如說我們可以把這樣的技術
加在各個電器裡面各個小家電裡面
這樣子它就會有
更多更多的應用可以跑出來
也可以使得每一個家電
每個物聯網設備有更大的能力
此外它也可以運用在
教育翻譯跟障礙輔助上面
因為Whisper模型的體積很小
所需要的系統也很少
所以它可以輔助翻譯輔助溝通
幫助有障礙的人進行轉譯
直到我錄影的此刻已經有相關的APP
已經有相關的教學軟體教學硬體
有相關的輔助硬體跟軟體
都已經在市面上使用
所以總結來說 Whisper模型
未來可能不會進入作業系統
而成為它的底層
而是進入各個小家電
各個電器各個電子設備
成為它們和人溝通的操作的核心
它們取代了已有的使用者交互介面
或是替代了原本沒有的使用者交互介面
而產生新的需求
所以在未來這樣子的功能
可能反而成為邊緣運算的小根基
由無數的小根基
連成出一個大大的邊緣運算系統
好啦那今天我們的聊天就到這裡
如果你想知道更多
歡迎留言和我聊天~我們下次見



