Nvidia推出語言模型 20241004,輝達推NVLM 1.0開源語言模型。能力大概和OpenAI的GPT-4o差不。媒體認是為了和Meta或者是OpenAI對打,我認為應該是為了A I的實際應用而開發,本篇包括:: NVLM、瞄準終端企業、AI的實體應用、聯發科7B模型等等。

Nvidia推出語言模型 影片
嗨我是亞瑟我有三高。今天要來講NVIDIA推出語言模型的大新聞!今天是2024年10月4號,我會快速為您整理這個新聞,並分享我的看法。歡迎跟我一起往下看。
NVLM 1.0

- 開源語言模型NVLM 1.0
- 評比約OpenAI GPT-4o
- 媒體主流報導認為
- 針對開源Meta LLaMA
- 我認為想實現軟硬整合
這一次推出的大模型名字叫做NVLM 1.0,它是一個開源語言模型。目前各方評價顯示,它的能力大概和OpenAI的GPT-4o差不多,非常厲害。
不過,由於它所需要的記憶體很大,我手上的伺服器沒辦法跑這個模型,無法做測試,但主流報導都認為它的能力相當不錯。
大家普遍認為它是針對Meta的Llama模型進行挑戰,但我覺得並非如此。我認為NVIDIA推出這個模型是為了實現軟硬體的整合,這才是它的核心目的。相關的技術報告可以參考下面的延伸資料。
NVLM-D-72B

- NVLM-D-72B旗艦模型
- 專精視覺和語言處理
- 開源模型權重與訓練代碼
- 視為挑戰Meta與OpenAI
- 前沿模型已達405B
https://bgr.com/tech/nvidia-stunned-the-world-with-a-chatgpt-rival-thats-as-good-as-gpt-4o/
NVLM-D-72B這個名字聽起來有點複雜,但基本上它是NVIDIA的旗艦模型,專門處理視覺和語言任務。根據網友的反應,它甚至能夠識別網路迷因,並找到其中的幽默點。
因為這是開源的,NVIDIA公開了模型的權重和訓練代碼,供大家參考使用。由於它的開源特性,大家認為這是一個挑戰Meta或OpenAI的舉措。
但其實它的亮點在於,它以72B的規模達到了和405B模型相當的能力,這是非常了不起的突破。只要有80G顯卡,像A100或H100,應該就能在本地運行這個模型,且性能和GPT-4o差不多。
瞄準終端企業

- 讓小公司導入AI
- 72B適合推論使用
- A100 H100 80G顯卡
- 利用有限資源導入AI
- 開源策略對小企業有利
https://dataconomy.com/2024/10/02/open-source-nvidia-nvlm-1-0-models
我認為NVIDIA的重點,不是擊敗智能模型的競爭對手,而是讓終端企業能夠更容易導入AI技術。
72B的模型大小適合用於推論,且能夠在中小企業能夠負擔的硬體上運行。例如,A100大約一萬美金,H100大約三萬美金,這對於中小企業已經是可負擔的範圍。
這樣的硬體加上開源模型,可以幫助小公司利用有限資源導入AI。唯一需要注意的是,目前這個模型的商業使用授權還不明確,後續再看看NVIDIA的計劃。
AI的實體應用

- Nvidia可能扶持合作夥伴
- 推動中小型AI模型開發
- 用於人工智能實際運用
- 機器人、自動化生產、自駕
- 在相容硬體上運行更流暢
- 類似CUDA硬軟整合模式
我也認為NVIDIA可能會扶持合作夥伴,像聯發科,推動中小型AI模型的開發。
這樣一來,更多公司可以使用這個開源模型,進行自己的優化和調整,應用於像是機器人、自動化生產、自動駕駛等領域。
未來NVIDIA的模型在自家硬體上,應該會更加流暢,並且可能像CUDA一樣,實現軟硬體整合,這或許也是一個軟硬體綁定的策略。
聯發科7B模型
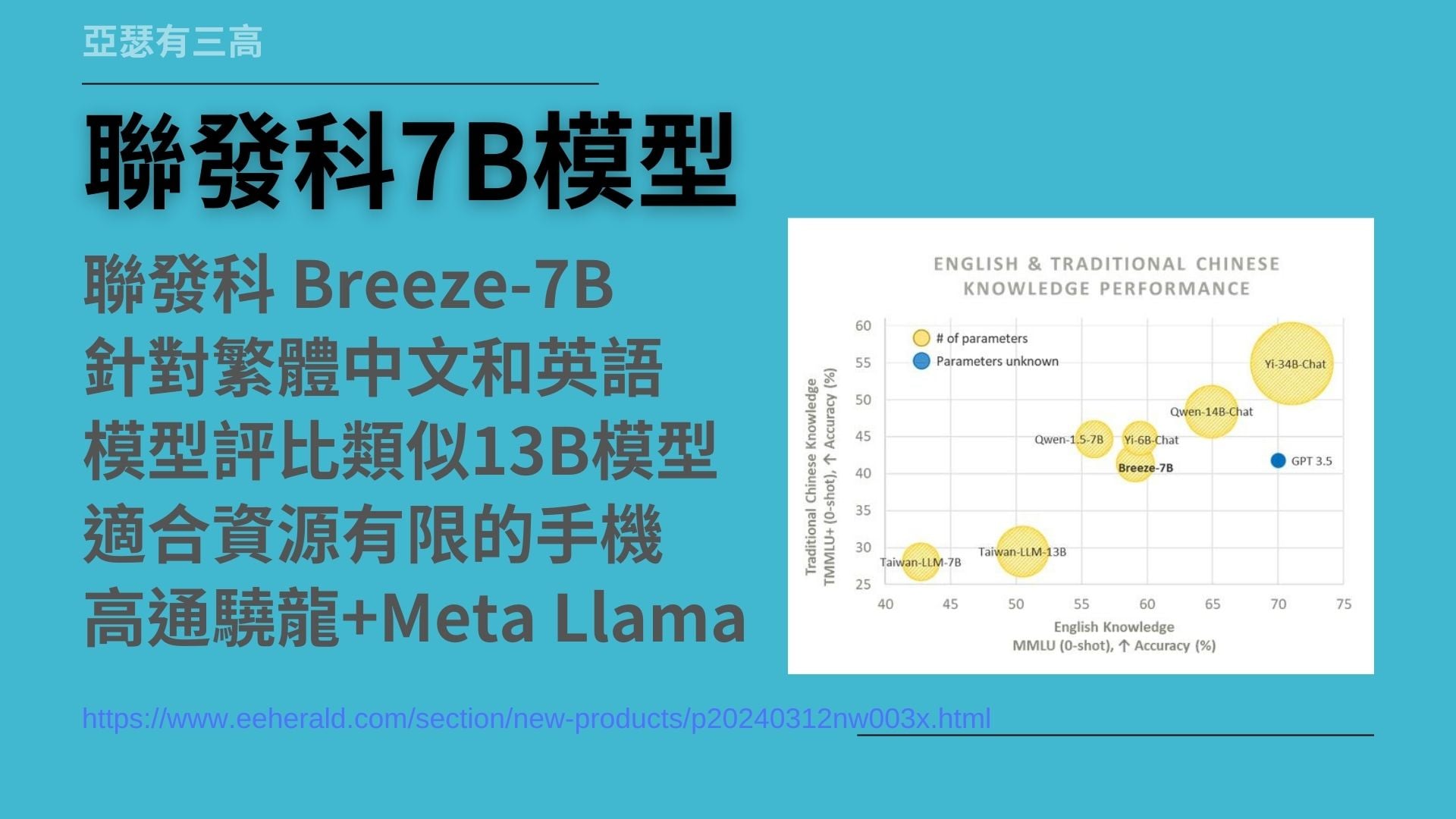
- 聯發科 Breeze-7B
- 針對繁體中文和英語
- 模型評比類似13B模型
- 適合資源有限的手機
- 高通驍龍+Meta Llama
https://www.eeherald.com/section/new-products/p20240312nw003x.html
接下來我們同場加映聯發科的7B模型。今年5月和9月,聯發科發表了Breeze-7B模型,以及後續的更新版版,這款模型針對繁體中文和英文進行最佳化。
根據媒體與我自己的測試結果,這個7B模型的能力,接近其他廠商的13B模型。
這對手機來說已經非常足夠,因為手機的資源有限,記憶體不大、CPU也不快。這類小模型的優勢在於,它能夠在有限的硬體資源上高效運行,如語音辨識和簡單的圖形處理。
目前驍龍平台也與Meta的Llama模型合作,不過可惜的是,目前安卓手機還無法實際測試這些語言模型。
Nvidia或有大計畫

- 黃仁勳偏好大方向
- 與聯發科可能有大動作
- 兩者推動AI實際落地
- 嘗試精簡智能模型的大小
- 增加終端硬體的運算能力
- 影響AI軟硬體整合發展
最後,我猜NVIDIA有一個大計劃,黃仁勳總是以大型計劃聞名。
NVIDIA這次展示了72B模型,達到405B模型的能力,而聯發科則用7B模型達到了13B模型的水準。
這可能意味著兩間公司,在未來會有更大的合作。他們可能會推動AI落地實現。一方面精簡模型大小,另一方面提升終端硬體的運算能力。
如果這些公司真的有新動作,我們會持續追蹤並更新。若真有好消息,那這很可能會撼動手機、AI以及個人設備市場。今天到這裡,Bye!



