ChatGPT是甚麼 拐點-萬維鋼 大震幅回來了 20240906,今天來講ChatGPT是什麼?內容持續是在『拐點』萬維鋼老師的這本AI著作中,會談到生成式神經網路 GenerativeNeural Networks、預訓練 pre-training、Transformer模型。

ChatGPT是甚麼 影片
ChatGPT是甚麼 大震幅回來了

- 大震幅回來了
- 生成式神經網路
- 預訓練
- Transformer
- 哲學上的跨越
- 神秘的神經網路
嗨我是亞瑟我有三高
今天來講ChatGPT是什麼
持續在拐點萬維鋼老師的這本AI著作中
我們讀的是第一章ChatGPT是什麼
先來看今日股市
大震幅回來了
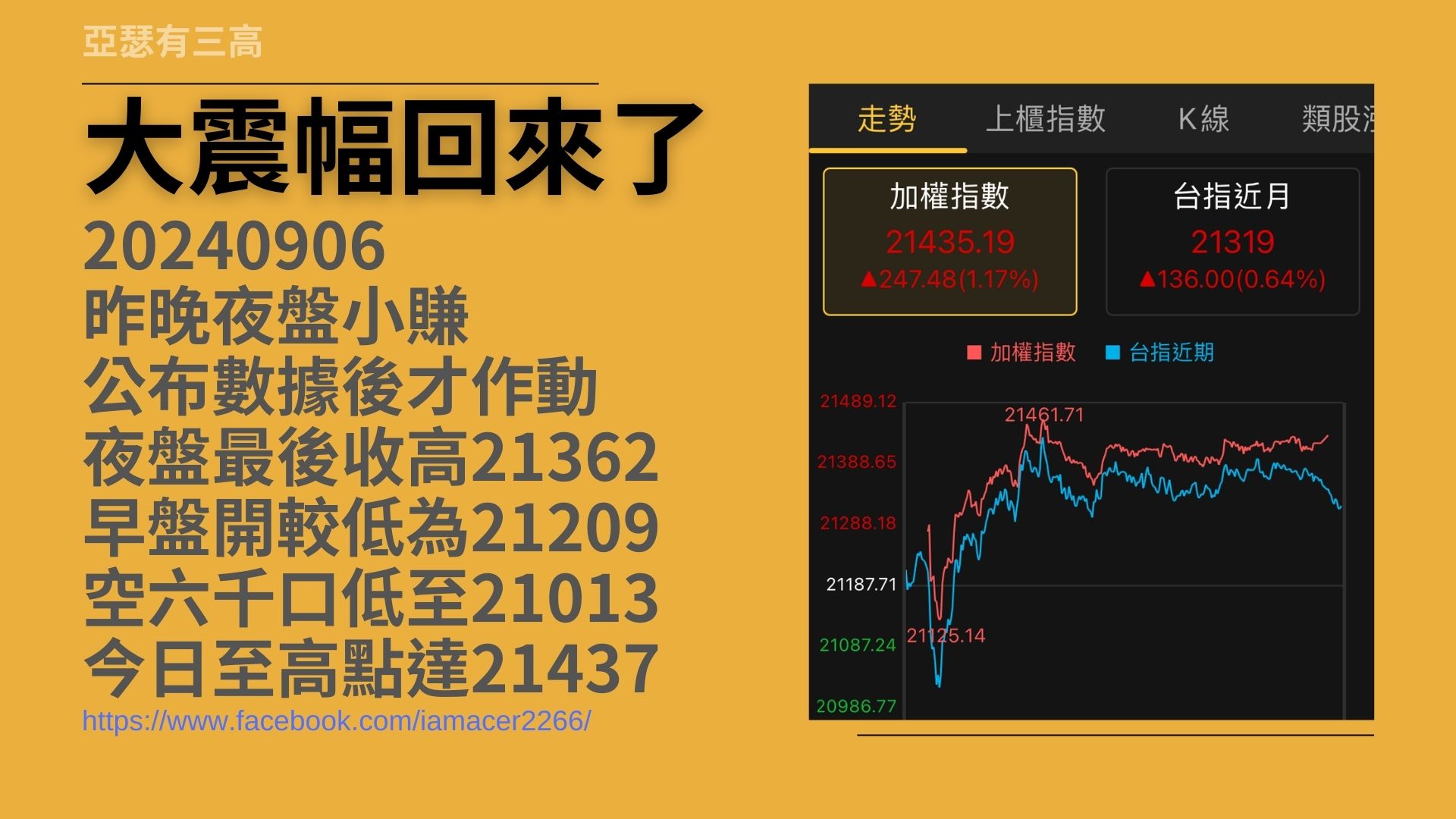
- 20240906
- 昨晚夜盤小賺
- 公布數據後才作動
- 夜盤最後收高21362
- 早盤開較低為21209
- 空六千口低至21013
- 今日至高點達21437
今天是2024年9月6號
昨天夜盤我是小賺的
做法是我先等公佈數據之後我才做動
因為現在常常不如預期然後大跌
不如預期也會大漲
如預期也跌如預期也漲
所以根本不知道數據出來之後會怎麼樣
那我直接放棄
我做後面那一段就好了
我比較沒有膽量
昨天夜盤也很詭異
昨天夜盤結束的時候
收蠻高的收21362
原本預期今天開的時候應該也是開362
結果沒有
今天早盤一開開比較低
開在209等於是消失了一百多點
所以還好沒有留倉過夜
盤前台積電就開始崩
所以從這邊開始就直接往下掉 很可怕
應該是幾分鐘之內六千口的空單
然後把當時的價格從
212多少一路打到21013
總共兩百多點
還好就是到底之後就反彈
所以反彈的時候我有稍微賺一小段
第二次反彈的時候我就沒有賺到了
因為今天的量一直沒有起來其實量很少
所以我一直覺得後面漲的這段不怎麼可靠
然後就沒有在積極做動當中
像最近的震幅就很大
像今天震幅就高達四百多點
那我自己非常喜歡這種 不要太快
然後台積電也不要上一千
這樣子一天震幅三四百點的這種盤
這種盤比較好做
因為做錯的話也無所謂 等一下就好了
這種盤比較好做
那今天早上聽那個交易醫生
他講他的盤前規劃跟他的做法
交易醫生的連結我放在下面
各位可以去文章後參考
他的東西比自由人再複雜一點
但是不管是自由人也好還是交易醫生也好
他們都是非常努力非常認真
而且讀非常多書的人值得學習
https://www.facebook.com/iamacer2266
ChatGPT是什麼

- Chat 交談介面
- Generative 生成式
- Pre-Trained 預訓練
- Transformer 語言模型
- 交談介面的生成式語言模型
回到這次的主題
那就是 ChatGPT 是什麼
這一次我把自己限制在『拐點』
萬維鋼老師這本書裡面
我們一章一章的往下讀
今天剛好讀到的是第一章
ChatGPT 是什麼
Chat 就是交談介面嘛
就是我們常看到的ChatGPT 聊天的介面
所以我們一直都以為他是聊天用的機器人
可是實際上不是啦
他只是用聊天的介面而已
GPT 的 G 是什麼呢
就是 Generative 它是生成式的意思
後面來解釋
那 P 就是預訓練 Pre-training
他有一些資料是先訓練好的
再來是 T 就是 Transformer
這是一個非常了不起的語言模型
Transformer 在這一節沒有好好地講解
我想在後面應該會有啦
簡單說 ChatGPT 是什麼呢
那就是交談介面的生成式語言模型
這邊每一段其實我都把一些延伸閱讀放在下面
在 YouTube 裡面貼這麼多連結不太方便
所以我貼在我的文章裡面
有興趣的話去我的文章裡面就可以點到
https://zh.wikipedia.org/wiki/ChatGPT
生成式神經網路

- GenerativeNeural Networks
- 互補學習目標的網路相對抗
- 生成器-負責生成內容
- 判別器-判斷內容的品質
- 二者隨著訓練互相進步
接下來我們對剛剛那個 G
就是生成式神經網路好好來解釋一下
它原文應該是 Generative Nature Networks
簡單說它就是互補學習目標的網路相對抗
聽到這個一定是傻了對不對
實際上它的想法很簡單
就是它會做出兩個大腦
兩個大腦實際上是用同樣的模式做出來的
只是它們的功用不同
一個大腦它負責生成
它負責生成內容
另外一個大腦它負責判斷
判斷這個生成的品質好不好
所以它每次生成一個內容的時候
也就是判斷它好不好 它關聯性強不強
不行就把它淘汰 行就把它留下來
而兩者就隨著訓練的互相不斷的慢慢進步
像是我們現在覺得
AI 會做創作
那就是因為它先生成一樣東西
然後自己再判斷這個東西
合不合使用者的需求
合就留 不合就把它刪掉
然後再生成一個再生成一個
這樣子反覆反覆反覆做
就可以把內容做得很不錯
而不斷的持續的學習
更多一點講
其實它學習了人類的大腦
就是第一大腦很快的先把事情想出來
而第二大腦再去想想看
這個東西對或不對
所以說說穿了它還是根基於我們之前
人類對於語言學對於腦神經學的研究
也就是說在這個 AI 這個年代
其實人類學語言學腦神經學
跟電腦 AI 資料庫
這些學問其實都已經摻在一起
而成為新的世界
那就是 AI 的世界
https://aws.amazon.com/tw/what-is/generative-ai
預訓練

- pre-training
- 以訓練翻譯為舉例
- 監督學習-標準答案範例
- 無監督學習-大量資料自學
- 強化學習-實做中改正錯誤
接下來談的是預訓練
預訓練的意思就是說
我們會先給 AI 一些我們給定的答案
有點像是小學的時候
我們先教小朋友一些最基本的語文
單字最基本的數學
最基本的國文英文
讓他們之後在學東西的時候
能夠靠這些基本的東西持續延伸下去
在這書裡面它是以訓練翻譯為一個範例
那我覺得這個範例真的舉得很好
不知道各位還有沒有印象
其實我們以前就有翻譯軟體
其實二三十年前就有翻譯軟體了
可是那個時候的翻譯軟體
它是直接把我們的英文和中文
直接對在一起
它會列出超長的列表
就是什麼英文應該對什麼中文 這樣對起來
可是後來發現這樣對不對嘛
所以怎麼辦它又發現了一些很多的情況
什麼情況之下英文要怎麼對什麼中文
所以我們那個時候可以發現
光是一個翻譯軟體
可能就高達五百MB六百MB
而且翻得還亂七八糟
但是時日今日透過了語言模型
例如說我們現在所使用的那個
ChatGPT 它會去理解我們的中文
還可以把它直接翻成英文
而那一個模型
基本上好像還不到五百MB而已
它不但可以聽得懂英 聽得懂中文
還可以中翻譯英翻中非常厲害
那怎麼做的呢
基本上分成三個部分
第一個部分叫做監督學習
這個時候我們會先給語言模型一些標準答案
例如像我剛才說的
我們會給它一些已經翻好的
什麼英文配什麼中文
我們可以把一些翻譯的書籍
或翻譯好的文章餵給它們
之後進入第二階段叫做-無監督學習
我們真的沒有辦法完全的舉例
什麼時候的英文要配什麼時候的中文
所以乾脆我給你一堆中文資料
一堆英文資料 什麼都給你
然後讓你自己
讓 AI 自己去學習 自己去了解
所以這個時候 AI 就會去
想辦法去拼湊我們語言的結構
而在 AI 的模型裡面
不斷的訓練不斷的訓練
它理解了我們人類語言的大結構
在 AI 的認知中
其實語言都是同樣的東西
講出的英文中文只是它表面的結構而已
AI 理解了這些結構之後
就會把它融會貫通
之後就會有非常不錯的翻譯成果
而這個翻譯成果
其實是比一開始
我們人類給定標準答案
好用非常非常的多
再進一步
我們希望翻譯軟體能夠更聰明
所以我們希望 AI 能夠翻得更自然
甚至還可以把一些我們隱藏中的情緒
把我們一些沒有在文字中
明白表示的東西翻出來
那怎麼辦
那這個時候我們就要提供它-強化學習法
也就是說AI 模型另外一個技能
那就是它自己去判斷
這個學習方式對不對
我們讓 AI 可以自己在實作中去改正錯誤
例如說 它翻了某些句子之後
使用者不喜歡就按不喜歡
這時候 AI 就會知道說
喔~這樣翻是不對的
那使用者如果說喜歡 它就知道說
喔~使用者說這個好
更令人常見的例子是開車
如果說今天 AI 稍微判斷錯誤了
它就會發現它偏離了軌道
變得危險一點點 就趕快把它改回來
所以從實作中就可以不斷地修正錯誤
那預訓練就包含了三個步驟
我們認為 AI 越來越聰明
越來越有智慧
其實很大的原因
那是因為強化學習的部分
使得它學會了我們當初沒有預期它會學會的東西
https://blog.csdn.net/weixin_45775438/article/details/136032397
Transformer

- 詞語跟詞語分別獨立
- 研究詞語互相的關係
- 以及隱含的深層意義
- 每個素材進來網路
- 各參數就會進行一次調整
接下來來到 Transformer
這個其實是一個語言結構
一個判別詞彙跟詞彙之間
關聯性以及隱含意義的一個結構
它出自於我們剛才前面提過的大作
Attention is all you need
在第一節裡面
當然不可能把這個講得太多
Transformer 應該可以用一本來講了吧
那簡單說 它就是呢
詞語跟詞語之間
對 AI 而言它是分別獨立的
例如說小明的小狗叫小白
它就會有『小明』『的』『小狗』『叫』『小白』
它會有這麼多的語詞會分別獨立
Transformer 模型它會互相去研究
每一個詞前後的關係跟關聯
這七個詞是可以互相前後調動的
或是更多的詞可以互相前後調動
它會去研究其中的關聯性
並且它還會去研究其中隱含的深層意義
而這個深層意義
是我們當初訓練它的時候所不知道的
它可能需要很多很多的訓練
很多很多的嘗試之後呢
它會去得出一個隱含的意義
擴展的意義出來
這個東西是我們人類目前完全無法預料到
它可以需要什麼程度的
所以說每一個素材
它投到這個 AI 網路之後
它就會對它做一個分析對它做個研究
每個參數進來之後
它就會做矩陣的運算
去求出它們每一個參數之間的關聯性
每個關聯性就會給高高低低的分數
甚至在每個關聯性的後面
它就會有隱含意義的研究
每多一些參數進來
就每多一次進行調整
我們給 AI 的東西就越多
AI 就越能理解我們到底在講什麼東西
甚至是更深層的意義
我前面曾經舉例過
用三句話去證明
去解釋 AI 怎麼把智慧做出來的
相關的內容就在螢幕上面我有貼出來
如果說有興趣的話
也可以在文章裡面找到連結往裡面點
我也會在螢幕的上面
看看能不能把相關的影片拉上去
今天的內容原本還有一大段
還有一半以上
因為我講書講太多 我就忘了時間了
沒想到已經
哇 如果都講完的話 可能要半小時了
所以我們就先卡在這裡
我們下一集再繼續講
這第一章的後半節
第一章的後半節
我們會講到 AI 的哲學性
AI 的神秘性 AI 的不可知性
然後還有 AI 的拓展
還有對於未來可能會有的狀況
今天是禮拜五 我們就禮拜一再見吧 Bye



