DeepSeek 中國AI突圍 20241230,Deep Seek V3,一款擁有 6710 億參數的中國語言模型,以 600 萬美元低成本訓練完成,性能超越 Llama 和 ChatGPT-o1。但數據來源與內容審查引發爭議,模型中立性與安全性備受質疑。

DeepSeek 中國AI突圍 影片
DeepSeek 噴發

- Deep Seek V3
- 中國大型語言模型
- 6710B參數超越GPT
- 訓練成本僅600萬美元
- H800 GPU低成本訓練
https://www.aisharenet.com/deepseek-fabule-v
中國 AI 公司 DeepSeek 推出了大型語言模型 Deep Seek V3,擁有 6710 億參數量。這數字非常驚人,且在許多測試中超越了 Meta 的 Llama 模型和 ChatGPT-o1。
更讓人驚訝的是,它只花了不到兩個月、不到 600 萬美元,且使用的是降規版的 H800 GPU 完成訓練。這意味著以極低成本和短時間,打造出媲美世界頂尖模型的產品。
這件事不僅在中國引發討論,也在全球科技、投資和 AI 圈掀起波瀾。甚至股癌謝孟恭也專門錄了一集 podcast 探討,因為這件事將影響市場情緒與股價走勢。
接下來,我會針對以下幾個主題進行分析:DeepSeek 的核心特性、技術亮點、質疑與擔憂,以及未來的發展與投資影響。
DeepSeek V3

- 是超大型語言 AI 模型
- 具備 6710B 高參數量
- 對中文理解能力特別優秀
- 使用 MoE 架構提升效能
- 能在各領域挑戰頂尖模型
https://www.meoai.net/deepseek-v3.html
簡單來說,這裡我們談的都是指 Deep Seek V3,也就是第三版。這是一個可以理解和生成語言的超大型 AI 模型。它不僅能回答問題、寫文章,還能寫程式。
而且,這個模型的最大亮點就是它擁有 6710B,也就是 6710 億個參數。但是為了運作效率,使用了一種叫做 混合專家模式(MoE) 的架構。
這架構很特別,它有 6710B 的參數,但是在回答不同問題的時候,模型只會啟動特定的「專家」,也就是大約 370B 的參數在運作。
拿 DeepSeek 跟其他模型相比,在很多方面的表現都更強。這樣不僅讓運算需求變小,也讓模型在需要時能發揮更大的效果。
這也是特性讓這個模型,在各個領域都可以分別擊敗,目前各類巨頭語言模型的原因。
特性與技術亮點
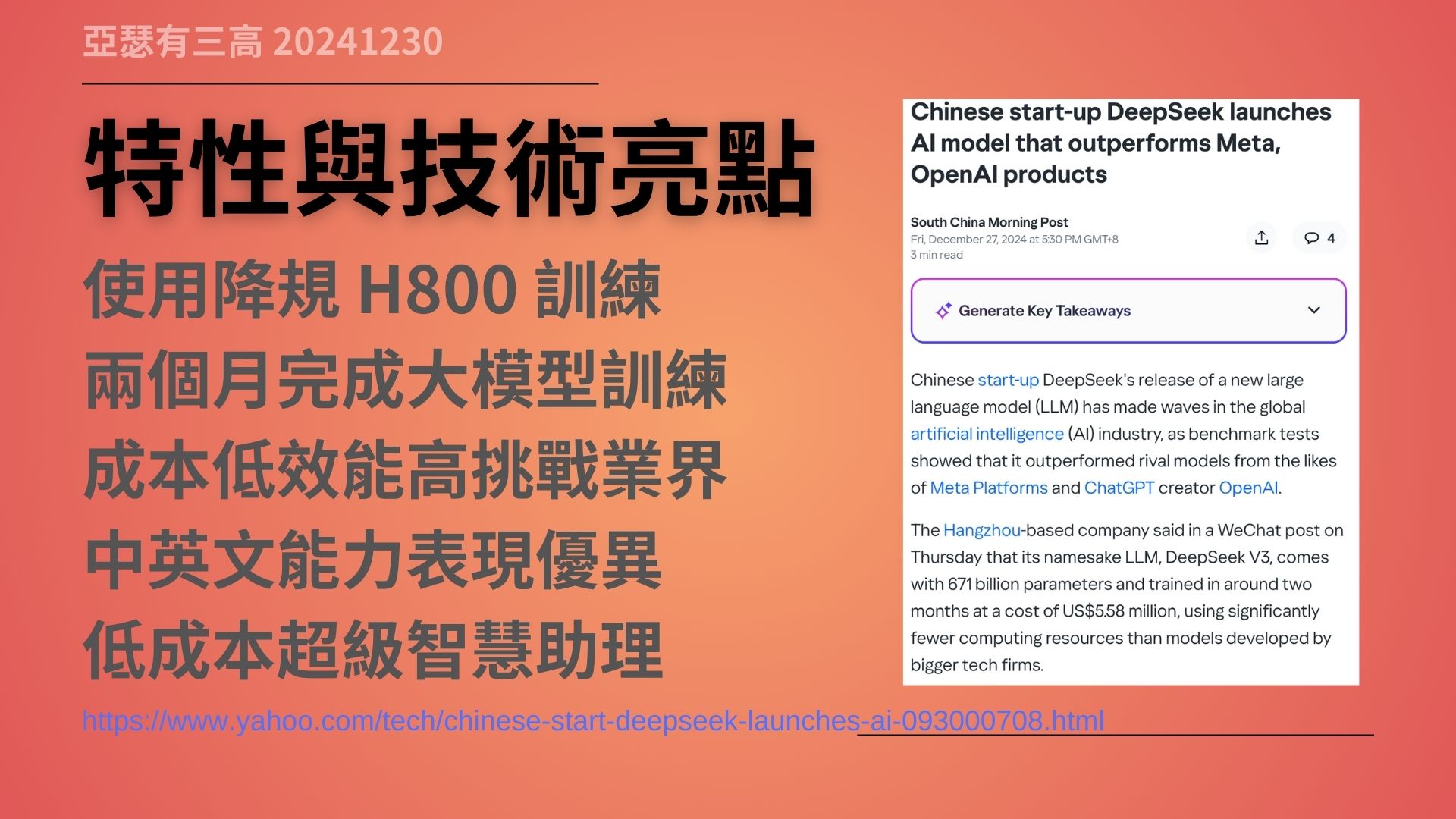
- 使用降規 H800 訓練
- 兩個月完成大模型訓練
- 成本低效能高挑戰業界
- 中英文能力表現優異
- 低成本超級智慧助理
https://www.yahoo.com/tech/chinese-start-deepseek-launches-ai-093000708.html
Deep Seek 的訓練方式非常特別。由於受限於中國的硬體條件,它使用的是降規版的 H800,而非頂級的 H100。H800 的運算能力和頻寬都被削減,可以說是被「閹割」過的硬體。
即便如此,只花了兩個月、不到 600 萬美金,就完成了超大型模型的訓練。這樣的效率和成本,對 AI 技術產業是一個很大的挑戰。
從目前的評測來看,DeepSeek 在回答問題、寫文章、生成程式等應用中表現出色,特別是在中英文能力上更是優異。它幾乎成為了一個低成本但效能極強的「超級智慧助理」。
很多人都在疑問,DeepSeek 如何用這麼有限的資源,打造出這樣的頂尖模型?如何控制成本又兼顧技術呢?
技術上的質疑

- 技術源自 Llama 模型
- 數據來源存在合法性疑慮
- 抄襲 GPT-4 成果引爭議
- 模型的原創性存有質疑
- 低成本可信度待驗證
https://techcrunch.com/2024/12/27/why-deepseeks-new-ai-model-thinks-its-chatgpt
DeepSeek 雖然表現亮眼,但也引發了許多質疑與擔憂。
首先,由於它是開放原始碼的程式,外界懷疑其技術來源可能來自 Meta 的 Llama 模型,而不是完全自主開發,更像是經過微調(fine-tune)的模型,這或許解釋了其低訓練成本。
其次,數據來源問題令人擔憂。405B 模型已耗盡大部分公開文字資源,DeepSeek 的 6710B 模型需要的數據量更為龐大,讓人懷疑是否使用了,未經授權或非法取得的資料,包括隱私數據或未授權的論壇內容。
另外,有人認為 DeepSeek 可能抄襲 GPT-4 的成果。測試中它有時會自稱為 GPT-4,這讓人懷疑它是否,反向利用 GPT-4 的生成結果進行訓練,引發版權與倫理爭議。
倫理與安全性

- 內容審查影響中立性
- 敏感議題缺乏真實性
- 可能對測試進行特化
- 容易受到越獄攻擊
- 長期使用可靠性存疑
https://www.ithome.com.tw/news/166720
內容審查是 Deep Seek 的一大弱點。由於其在中國開發,受到言論審查影響,對天安門事件或台灣等敏感話題,可能直接過濾或以偏頗的立場回答,甚至否認某些事件的存在,讓人懷疑模型的中立性與真實性。
此外,有人懷疑是否針對測試的問題,對模型進行特化與優化,這讓測試結果看起來特別優秀,未必反映實際應用的表現。
安全性也是一大問題。測試者發現它容易被越獄攻擊,可能生成不應該輸出的內容,如毒品製造方法或非法駭客的方法,長期使用的可靠性構也是疑慮。
低成本模型是否能,在長期使用中保持穩定、安全,並且符合社會的核心價值觀,這是值得關注的問題。
語言架構新發展

- Scaling Law已達極限
- 單純依靠文字智能受限
- 多模態將成未來突破
- 多模態訓練處理仍需提升
- 高算力需求成未來門檻
https://arxiv.org/html/2402.12451v2
語言模型真的到瓶頸了,Scaling Law 已經碰到極限,單靠文字發展智能已經不行了。
目前 ChatGPT 並不是更聰明,而是靠「思維鏈模式」或「反覆提問」來讓答案更準確,甚至直接搜尋網路來修正錯誤,其實沒有真正的大突破。
下一步一定是多模態,但多模態不是只生成圖片而已,而是從真實世界的數據中學習和訓練。這方面進展還很初步,雖然能看圖片,但回答還是不夠準,對人類社會的理解也很膚淺。
圖片數據的資訊量很大,但要進入多模態訓練階段,伺服器和算力的需求會是現在的幾十倍,這才是後面面對的成本和技術挑戰。
所以,語言模型的下一步不是拼參數,而是訓練多模態數據來突破瓶頸。但要做到這點,技術和算力的門檻會變得非常高。
投資方面的影響

- 語言模型發展達到瓶頸
- 多模態訓練成為新方向
- 市場信心因差距受影響
- 科技巨頭將持續投入AI
- 信心低點可能是進場機會
https://www.cw.com.tw/article/5132716
語言模型現在到了瓶頸,科技巨頭的目標也開始轉向多模態訓練。不過,這也帶來市場信心的波動。
當中國的文字模型超越美國時,美國科技巨頭的市場信心自然會受影響。AI 伺服器或晶片的需求,是否能持續成長,成為一個疑慮。
當多模態模型真正起飛時,伺服器和算力需求會暴增。硬體需求如果翻十倍,像中國這樣的追趕者,恐怕連模仿的機會都沒有,因為資源和門檻實在太高了,這也會進一步鞏固美國巨頭的護城河。
短期市場可能會因信心動搖而波動,但長期來看,AI 投資仍是科技巨頭無法放棄的方向,這不是選擇,而是必須走的路。而對投資人來說,市場信心回落時,可能正是進場的好時機。



