GPT-4o 如何看懂你的圖? 語意空間與token,GPT-4o 不只是會畫圖,而是能「理解你圖裡的意思」,再根據語意重新生成畫面。本片完整解析它如何把圖片切成 token、如何運用語意空間理解圖像內容,再用語言生成方式畫出新圖。這是語言模型第一次真正學會「看圖說話」。

GPT-4o 如何看懂你的圖 影片
最近經歷了ChatGPT的繪圖之亂
大家都用它來做AI生圖
很厲害非常好用
但是為什麼它可以這麼厲害
實際上我去看了
OpenAI的報告之後呢
覺得好像什麼都沒提
而且網路上面也沒有太多的資訊
那怎麼辦?
我就去問ChatGPT
我跟他討論了好幾個小時
請他圖文並茂地告訴我他怎麼做到的
然後我們就有了今天這一個影片
我是亞瑟我有三高
每週一到每個禮拜五
我都會分享學到點點滴滴
那這一集我們很特別
不是引用一堆網路上的搜尋結果
不是!
這一集基本上是靠
ChatGPT慢慢教我的
我們開始吧
語言模型會畫圖
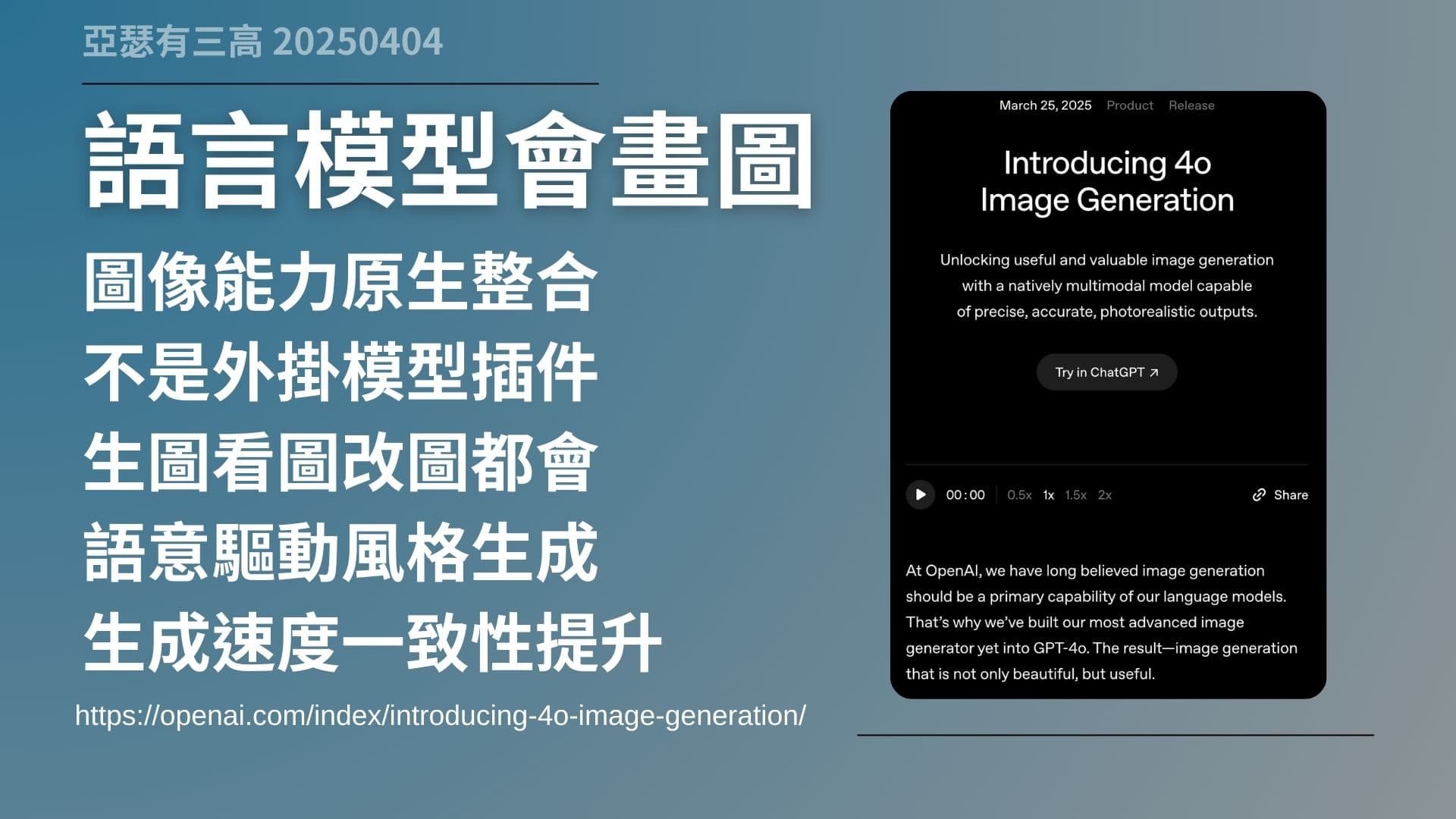
- 圖像能力原生整合
- 不是外掛模型插件
- 生圖看圖改圖都會
- 語意驅動風格生成
- 生成速度一致性提升
https://openai.com/index/introducing-4o-image-generation
這次 GPT-4o 的生圖能力,跟以前最大的差別就是,它不是另外裝一個外掛,也不是在後台偷偷幫你呼叫 DALL·E 來畫圖,而是這次整個「畫圖的能力」是直接內建在模型本體裡的。
這表示什麼?它聽你講話的時候,就已經在準備畫圖了。而且它不是只會畫圖,它還可以理解圖,像是你給它一張圖,它會知道裡面是什麼,甚至能幫你改圖、幫你續畫下去。
這個等於是語言模型跟圖像模型直接整合,這不是以前的那種切換模式,這是全新的運作邏輯。你講的話、你給的圖,它都當作「對話」的一部分來處理,所以整體互動感完全不一樣。

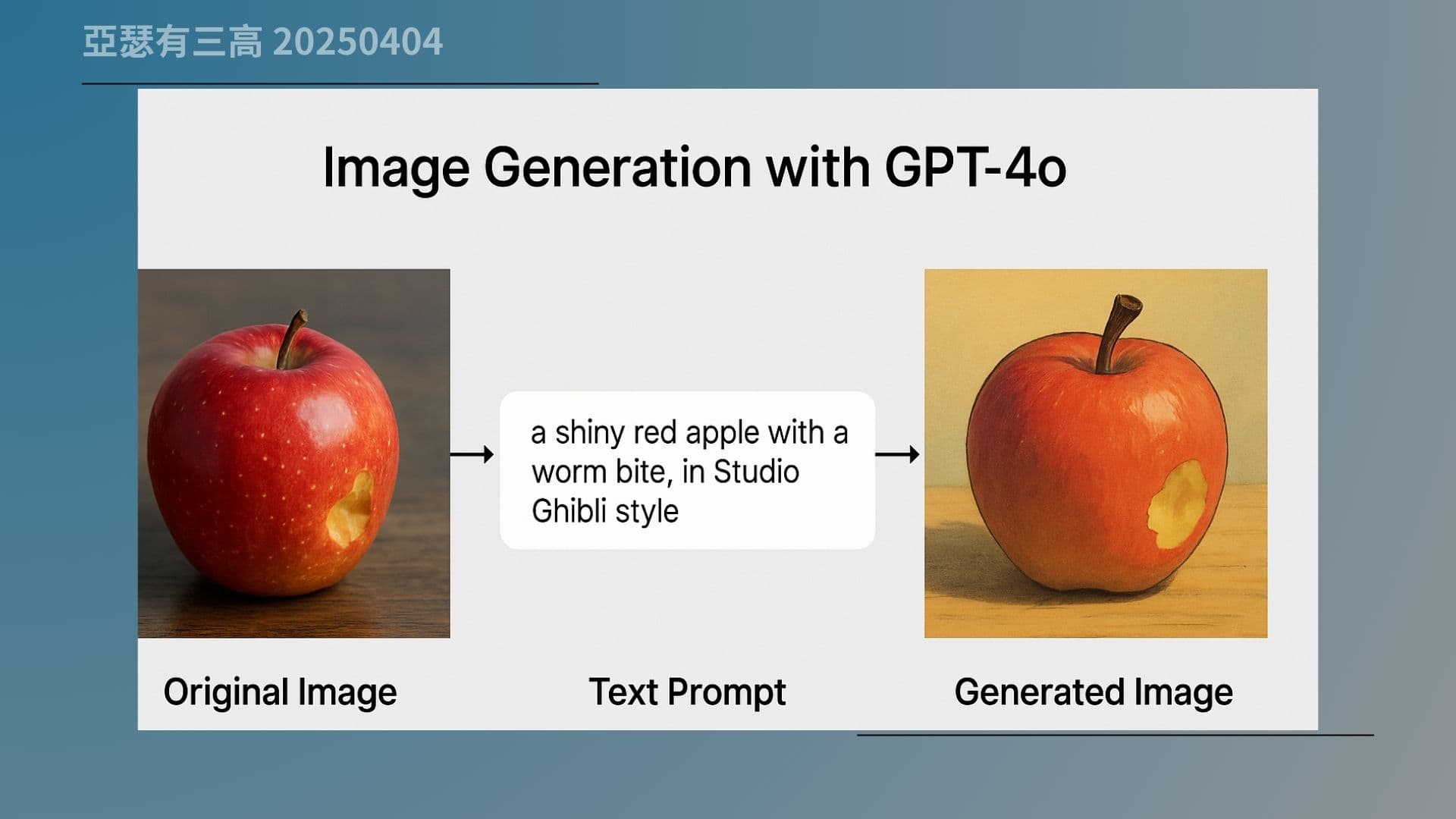
那我們來看一下這張圖。左邊是原始的蘋果照片,右邊是 GPT-4o 幫你重新畫出來的「吉卜力風格的蘋果」。你會發現它不是把原圖加個濾鏡,而是真的重新畫一顆蘋果,而且符合你講的風格、光影跟畫法。
這也說明,它其實不是圖片處理器,而是「用理解去畫出圖像的語言模型」。
圖像被切成格子

- 切成小塊轉為 token
- 每塊代表圖像特徵
- 圖像與文字共用格式
- 轉換後可同時運算
- 視覺語言統一處理
我們現在來講一個比較技術的地方,就是 GPT-4o 是怎麼「看圖」的。因為它不是用人類那種方式去看整張圖,它的看法比較像在「拼圖」。
一張圖片進來,它會先把它切成一塊一塊的小區塊,通常是每塊 16×16 像素。每塊就像是一個視覺單位,然後這些小塊會被轉成 token,也就是說,它把一張圖變成了一串可以處理的圖像資料。
這些 token 沒有語意,但會帶有顏色、紋理、位置等特徵,對 AI 來說,它就是透過這些拼出整張圖的。最重要的是,因為這些 token 跟文字 token 格式一致,所以圖像也可以「當作語言的一部分來理解」。

你現在看到這張圖就是整個流程的視覺化說明。左邊是一張蘋果圖,接著被切成很多格子,每一塊都代表一組圖像資訊。然後這些格子會變成 token,一路送進模型中處理。
這個過程就是 GPT-4o 怎麼把一張圖轉成「語言模型能理解的格式」。這也為後面它能理解圖片、重畫圖片,打下基礎。
先講出這是什麼

- 圖片變語意描述
- 模型主動講出內容
- 不是背答案是理解
- 建立多層級語意連結
- 圖文理解同時建立
GPT-4o 在處理圖片時,不會直接拿圖去生圖,它會先做一件事,把圖片「翻譯成語言」,也就是說,它會先試著「講出這張圖裡面是什麼」。
這聽起來很簡單,但其實就是語言模型第一次,「看懂一張圖」的關鍵。像你給它一張蘋果圖,它可能就會講出:「一顆閃亮的紅蘋果,上面有一小塊咬痕,放在木頭桌面上」。
這不是資料庫裡查出來的句子,而是它真的「看圖說話」。這個過程叫做 image captioning,是目前所有多模態模型裡面很重要的一步,因為只有先能夠講得出來,後面才有辦法做風格轉換、圖像續寫、甚至修改。

來看這張圖,你可以看到原本的蘋果圖在左邊,右邊是 GPT-4o 根據這張圖,自動生成的一段文字描述。它不是單純講「這是蘋果」,它還會補上「亮紅色」、「被咬過」、「放在木桌上」這些細節。
這種描述能力不是把圖做分類,而是真正用語言理解畫面內容,這也就是為什麼它能夠像人一樣對圖做出有邏輯、有層次的反應。
語意轉成新圖像

- 從語句畫出畫面
- 不是改圖是重畫
- 語意轉換風格圖
- 風格控制靠 prompt
- 用講的決定畫法
接下來就進入 GPT-4o 最關鍵的生圖流程。
剛剛說過,它會先講出圖片內容,那現在,它會反過來做一件事,就是「根據你講的語意,再畫出一張新圖」。這個過程不是改原圖,不是修一修,而是從頭重新畫一張,畫出你講的內容。
也就是說,GPT-4o 生圖的起點不是圖片,而是「語言描述」。你給它一句話,它會根據這句話的內容,決定每個 token 要怎麼組合,畫出來的畫面才是你真正想要的。
而且你還可以加上風格提示,像是說「幫我畫成吉卜力風格」,它就會照那個語氣去畫。
你現在看到這張圖,就是這個過程的範例。左邊是 GPT-4o 先分析圖後講出來的語意,中間是你給的指令,比如「用吉卜力風格畫」,然後右邊就是它根據這些語意與風格,完整重新畫出來的新圖。
這不是圖片加濾鏡,也不是修飾,這是真正的用語意來重新生成,這就是 GPT-4o 最厲害的地方。
打敗 Diffusion

- Diffusion 是降噪流程
- AR 是一步步預測
- 語意控制更穩定
- 生成速度與準確性高
- 模型理解能力更強
過去我們講到 AI 生圖,最常提到的就是 Diffusion 模型。那種模型的原理其實就像「黑白底片顯影」一樣,一開始給你一張亂七八糟的雜訊圖片,然後一步一步把雜訊降下去,慢慢還原出一張圖。
但問題是,這種方式不但很慢,而且很多時候你給它的語意指令,它也不見得能準確抓住,尤其在角色一致性跟細節控制上非常不穩。
而 GPT-4o 用的不是 Diffusion,而是自回歸(autoregressive)方式。它是像在講一句話一樣,一個 token、一個 token 地拼出畫面,也因此它能夠更準確地把你的語意反映在畫面上。你講得越清楚,它畫得就越像。而且生成速度也明顯快很多。

來看這張對照圖就很清楚。左邊是 Diffusion 模型的流程:從雜訊一路降噪,最後還原成圖片。右邊則是 GPT-4o 的流程,它是直接從你講的語句出發,一步一步預測圖像 token,然後慢慢把整張圖畫出來。
這個方式不只更快,它在風格穩定、圖文一致性上,也遠比 Diffusion 模型更好控制。
懂內容才能改圖片

- 不是補圖是重畫
- 先理解再動手修改
- 圖中區塊有語意
- 語意控制修改範圍
- 生成自然且一致
如果你以前用過 AI 修圖,就知道傳統的 inpainting 功能是怎樣,你圈一塊地方,AI 幫你補上去,可能顏色對了,可是看起來就是怪怪的,像拼貼上去的。
為什麼?因為它不是真的「知道你要改什麼」,只是試圖在那塊區域找個合理圖案塞進去。
但 GPT-4o 的改圖能力完全不一樣。它不是「補」,而是「重畫」。而且它會先把整張圖理解一遍,確認哪裡是主體、哪裡是背景、什麼東西跟什麼東西有關,然後才去動那一塊。
所以當你說「把這個人的頭髮改成紅色」,它會知道什麼是頭髮、什麼叫紅色,然後整體畫面也會一起跟著調整。
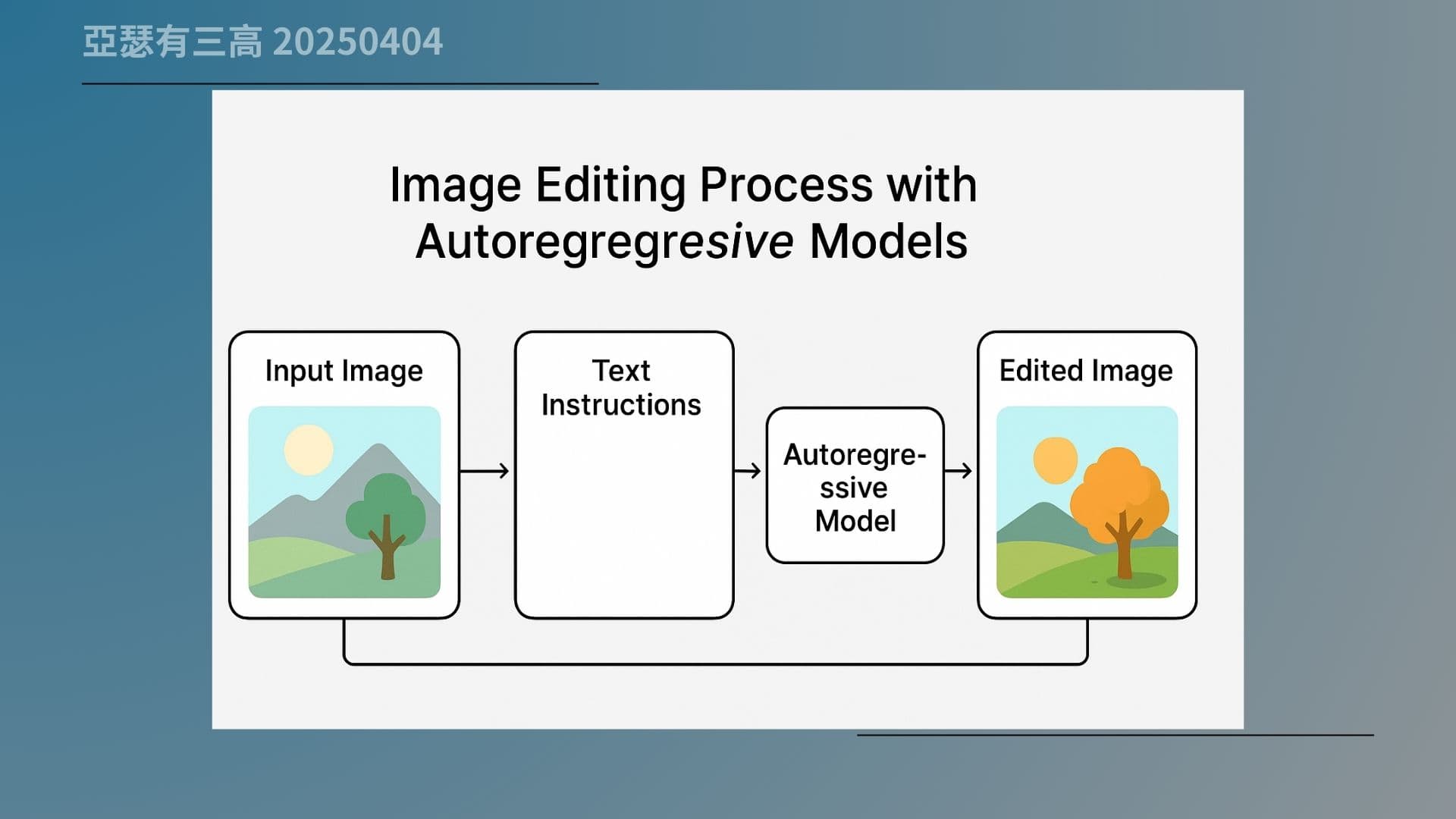
你現在看到這張流程圖就能理解這個差別。左邊是原圖,中間是你圈選區塊、輸入修改語句,右邊是改圖後的結果。
你會發現,這個改圖不是單純補一塊,而是根據整張圖的語意重新去畫。這就是語意層級的修改邏輯,效果更自然、也更一致。
學到的是語意空間

- 不同蘋果不同方向
- 語意空間有維度
- 懂你要的是哪一種
- 不記圖而記特徵
- 蘋果家族有定位
很多人以為 AI 在生圖的時候,是記得「一張蘋果圖長什麼樣」,但實際上不是。GPT-4o 真正記住的不是圖片,而是「概念的空間位置」。
意思是,它看過各種蘋果,例如:紅的、綠的、咬過的、爛掉的、切開的、做成果派的……每一種都會被放進語意空間裡,變成某個方向、某個位置。
這個空間有點像地圖,你講出一個關鍵詞,它就知道要往那個方向去找一個圖像的表現方式。你講「青蘋果」和「蘋果派」,它就能畫出很不一樣的東西,因為這兩個詞在語意空間裡距離很遠。
這也解釋了為什麼 GPT-4o 能這麼靈活地,處理不同語境下的圖像生成。
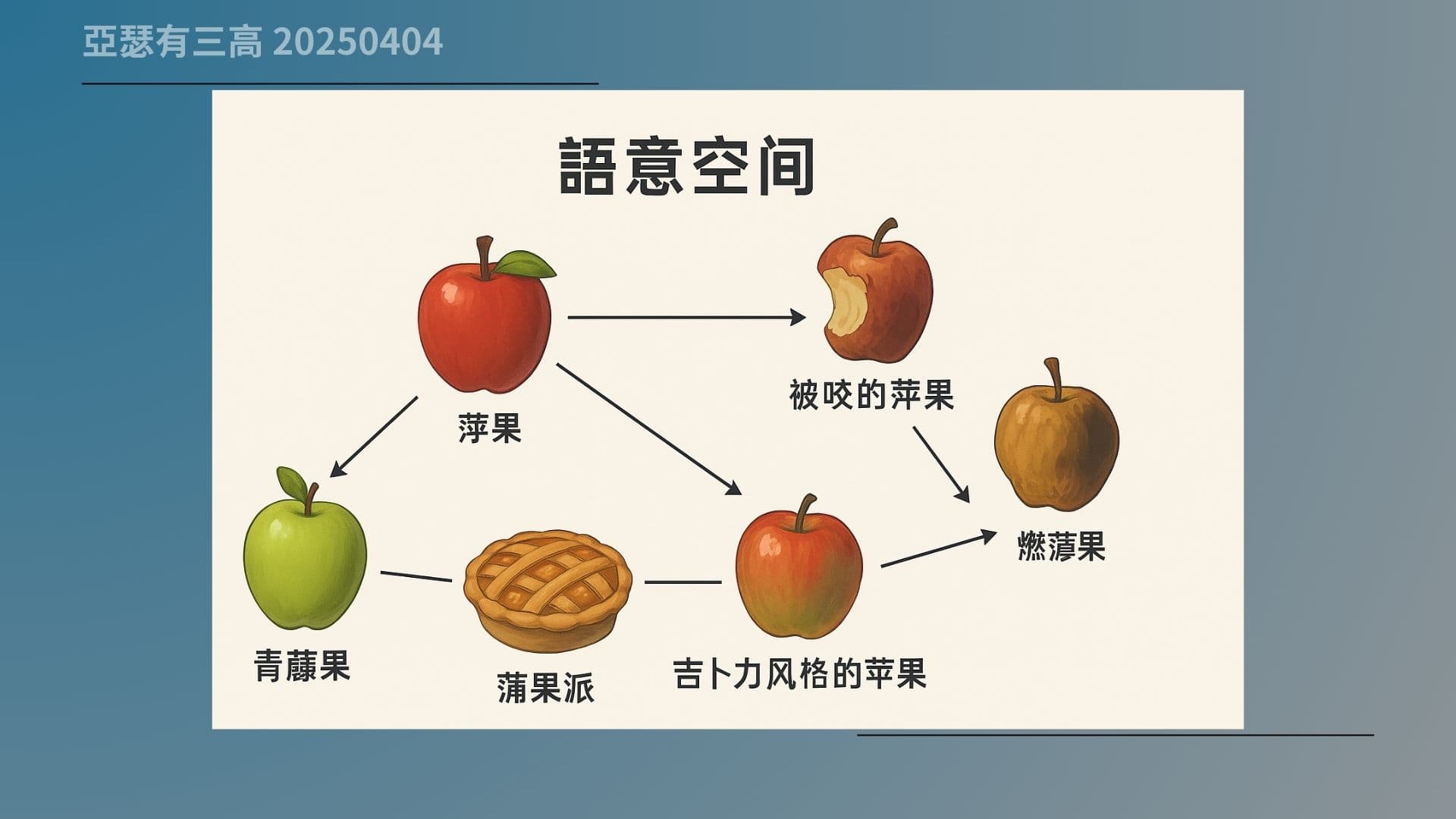
你現在看到的這張圖,就是一個語意空間的示意圖。裡面有「蘋果」、「青蘋果」、「爛蘋果」、「被咬的蘋果」、「蘋果派」,甚至還有「吉卜力風格的蘋果」,它們彼此之間在這個概念空間裡是有方向、有距離的。
GPT-4o 就是在這個空間裡,找出你講的那一類蘋果,然後根據那個語意位置畫出來。這不是把圖分類,而是把語言跟圖像,變成空間邏輯的一部分。
萬物都變token
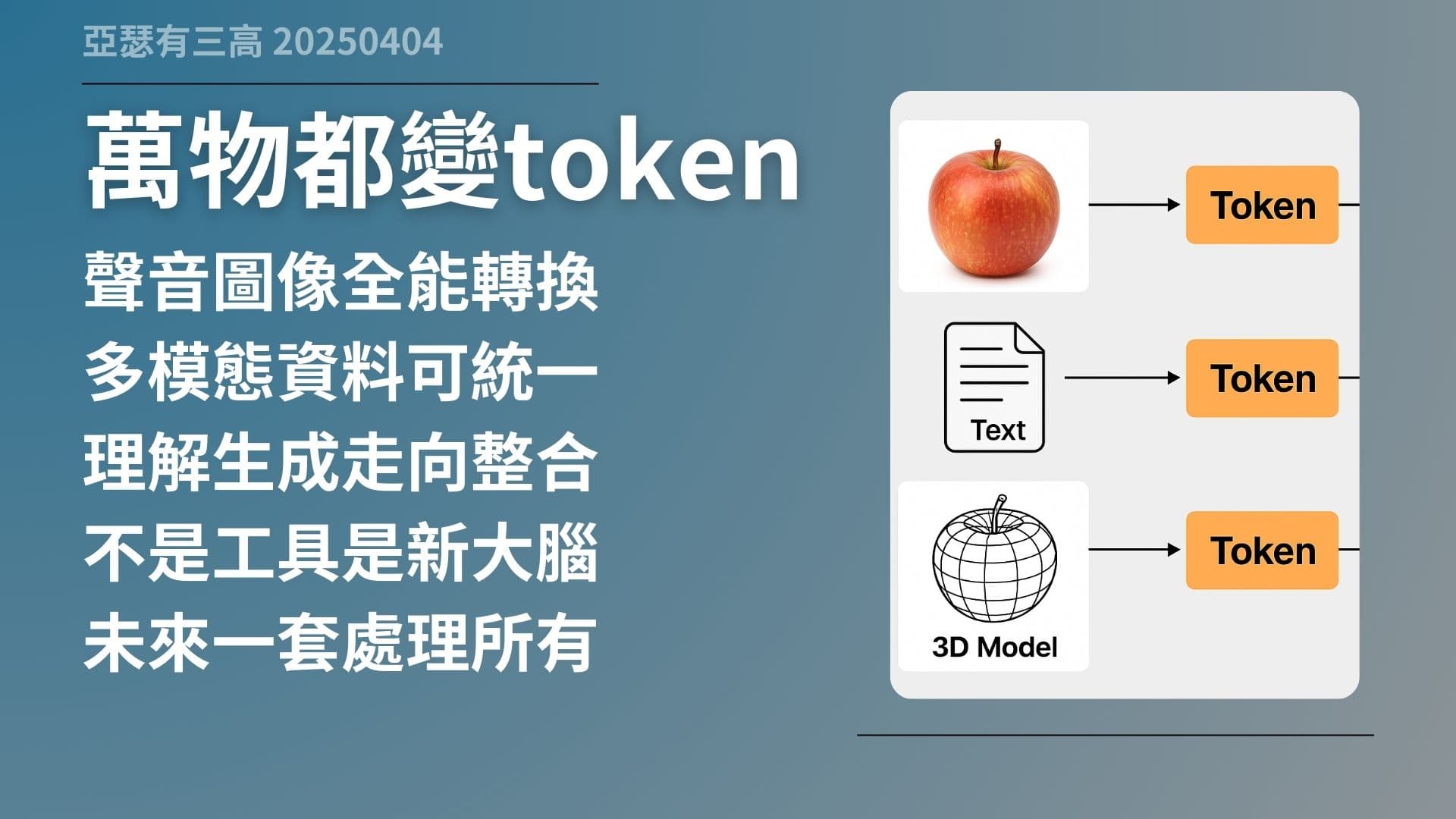
- 聲音圖像全能轉換
- 多模態資料可統一
- 理解生成走向整合
- 不是工具是新大腦
- 未來一套處理所有
GPT-4o 展現出來的,其實不是「AI 又多一個功能」,而是代表一個新方向,只要任何東西能夠轉成 token,它就能學、就能理解、就能處理。
圖像可以切成 patch,變成 token;聲音可以轉成頻譜片段,也可以 token 化;影片、3D 模型也一樣。也就是說,不管你給它什麼資料,只要轉換格式對了,它都能用同一種機制處理。
這不只是圖文多模態,而是走向「全模態整合」。你想想看,一個模型能處理聲音、圖像、文字、影片、甚至動作與空間邏輯,這個東西已經不只是工具,而是我們真正意義上的「AI 大腦」。
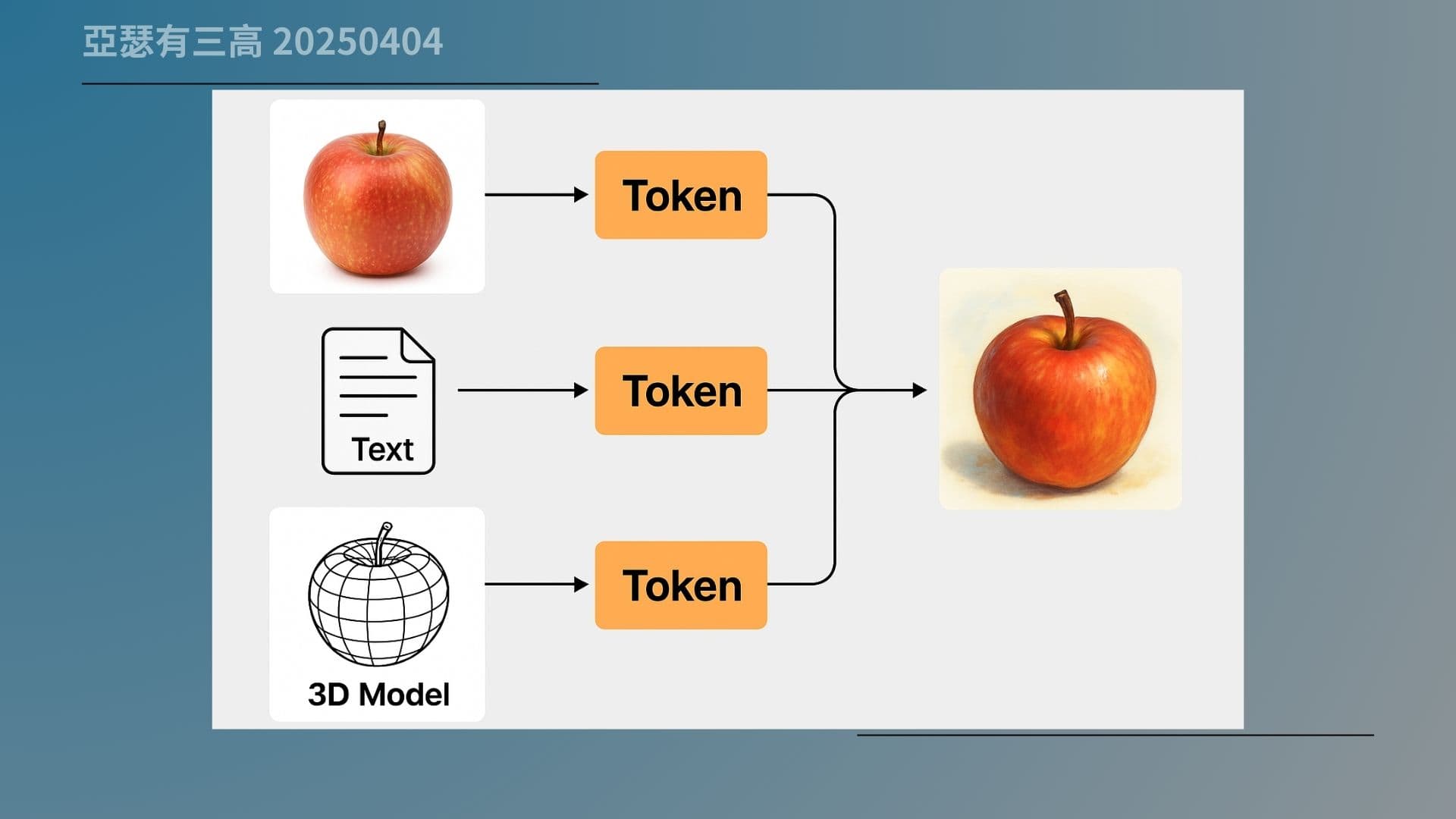
那我們一起看這張整合圖。左邊是各種資料型態:聲音、圖片、影片、3D 模型,每一種都可以切成片段、轉成 token;右邊則是 GPT 模型,把這些資料一起處理進來,統一理解。
這整個流程就代表未來的方向:萬物皆可 token,一個模型全都搞定。GPT-4o 是第一步,下一代只會更整合、更強大。
在這邊也可以再延伸一下
GPT-4o的Advanced Voice
其實也就是用一樣的方式來做處理的
那麼如果再往前推一點點
是不是就可以
把影片的功能也加進去了呢
所以我想十之八九
也是用一樣的方式來做處理
只是ChatGPT目前光是處理一張圖片
就已經算力不足了
不能夠再讓大家隨便加入
音樂、聲音、影片擋進去
不然他們更撐不住
在這邊就可以大致上推論出來
ChaitGPT-4o也許已經
準備好了非常多的多模態
只是目前的算力根本撐不住
要不就是把這台算力
乘以十、乘以百、乘以千
繼續發展下去
要不就是要開發出
更好的模型、更好的處理機制
來處理這些東西
那麼我們不管怎麼樣都拭目以待
對了後面就讓各位欣賞一下
最近我們合成家裡面寵物的照片



